Before we start our journey we need to know what OpenVDB really is. From their web page we can learn that:
OpenVDB is an Academy Award-winning C++ library comprising a hierarchical data structure and a suite of tools for the efficient manipulation of sparse, time-varying, volumetric data discretized on three-dimensional grids. It is based on VDB, which was developed by Ken Museth at DreamWorks Animation, and it offers an effectively infinite 3D index space, compact storage, fast data access, and a collection of algorithms specifically optimized for the data structure for common tasks such as filtering, CSG, compositing, numerical simulation, sampling, and voxelization from other geometric representations.
Managing volumetric data in computer animation and especially in visual effects is wide spread and thanks to OpenVDB it shares one common format. Being an industry standard, exchanging data and working with multiple tools on the same data set makes it a breeze with OpenVDB. The real benefit for the visual effects artists stems from its wide spread use and acceptance in larger and even smaller studios.
Once understood, the OpenVDB tool-set feels the same in every place and the visual effects artists can concentrate on his main task: Being Creative in his work!
Yes, and no. Volumetric lighting effects are cool and such but volumes are made for so much more! Signed Distance Fields (SDF) for example are also volumes, they are actually a volumetric representation of where a surface would exist in a volume. A simple mesh object can be easily turned into its own volume representation by creating a SDF out of it. Why would you want that, you may ask. Working with volume data offers huge advantages when it comes to modification, manipulation and speeding up visual effects tasks especially when using narrow band and sparse volume representations.
Fluid simulations are one of the examples to benefit from highly optimized volume data access and handling. Complex fluid simulations take an enormous amount of processing power, and once those calculations are done it is best to store and access this simulation data in the most efficient way. Manipulating an existing volume data set after the fact is also an added bonus no visual effects artist will ever say no to.
As mentioned before, any mesh can be turned into a volumetric representation of itself. Once a mesh or polygonal object becomes a volume your imagination is the limit! Mathematical manipulations on volumes are easy and robust operations to perform and allow us to do all kinds of effects on volumes that would be impossible otherwise.
A volume Grid in thinkingParticles is usually a box with all its data attached to an individual particle. Position, size, and orientation is all derived and manipulated by the 'field particle'. Volume Grids are subdivided into smaller boxes called voxels, with a value stored in each voxel.
Volume Grids can store all kinds of information in their voxels:
Scalar Volume Grid
Each voxel stores a single numeric value in 3D space, for example a density value can be used to describe smoke or cloud effects. The higher the density the less transparent a cloud or smoke could appear in the volume Grid.
Signed Distance Field (SDF)
This type of volume Grid stores distance values to a given surface as measured from any point in the volume Grid. All points outside the surface will have positive distance values, points inside will show negative values. The surface itself will have 0 as its value in the volume Grid.
Vector volume Grid
Each voxel will store a vector as 3 values (X,Y,Z) in the volume Grid. Some applications however will deliver vector fields as 3 separate scalar volume Grids
Vector volume Grids are great for avoidance force fields or velocity fields that modify or influence a particle's speed as it travels through a volume Grid.
Color volume Grids are treated as vector volume Grids, the three values in this case represent R,G,B values of a color instead of a vector.
Boolean Volume Grid
Boolean volume Grids are a special purpose type of volume grid. Each voxel stores a True or False value that can be used as a mask for example.
PointDataGrids
This type stores points with attributes directly in a VDB Grid. Using this storage mechanism, points are spatially-organised into DB voxels to provide faster access and a greater opportunity for data compression compared with linear point arrays. In short - finalRender gives you all the benefits and power of the fastest point data handling on the market. It fully supports multi-threading and is highly efficient in storing and handling point data.
The below paragraph is a collection of descriptions deemed to be relevant for finalRenders' integration of OpenVDB. Be warned, some of the descriptions depict the internal makings of a volume Grid which is usually not relevant to the visual effects artist but it might give some extra depth and understanding to why things are the way they are.
finalRender supports Point rendering through NanoVDB, and there are many 'external' ways to generate VDB grids with point data in it. OpenVDB files containing point grids can be read and rendered with finalRender. One other way is to generate point data right inside of 3ds Max with thinkingParticles.
thinkingParticles automatically creates certain data used in a PointData grids. Radius is controlled by particle Size and the point position uses the particle Position. To control the point color, create a DataChannel on the particle group called "Cd" and store this in the PointData grid using InputFromVDB's "In From" drop-down. An OpenVDB PointDataGrid in thinkingParticles consists of:
- position; added automatically
- Normal (alignment world -z axis of the particle); added automatically
- Radius; added automatically
- Velocity; added automatically
- Optional: Color which must be supplied in a separate Grid named Cd
OpenVDB stores voxel data in a tree like structure with a fixed maximum height, with a root node that has a dynamic branching factor, with internal nodes that have fixed branching factors, and with leaf nodes of fixed dimensions. Values can be stored in nodes at all levels of the tree. Values stored in leaf nodes correspond to individual voxels; all other values correspond to "Tiles" .
Every value in a grid has a binary state that is referred to as its "active state". Active voxels are considered to be the only relevant voxels in a grid. For example, the values in a narrow-band level set are all active, and values outside the narrow band are all inactive. Active states of values are stored in very compact bit masks that support sparse iteration, so visiting all active (or inactive) values in a grid can be done very efficiently.
Values stored in nodes of type LeafNode (which, when they exist, have a fixed depth), correspond to individual voxels. These are the smallest addressable units of index space.
Values stored in nodes of type RootNode or InternalNode correspond to regions of index space with a constant value and active state and with power of two dimensions. We refer to such regions as "tiles". By construction, tiles have no child nodes.
A tree's background value is the value that is returned whenever one accesses a region of index space that is not explicitly represented by voxels or tiles in the tree. Thus, you can think of the background value as the default value associated with an empty tree. Note that the background value is always inactive!
You can imagine a voxel grid as a collection of solid cubes, all stacked on top of each other. However, the information stored in those cubes is not in the cube itself, information is only stored in the center point of the cube. The size of those cubes is equal to the voxel size and the smaller this size, the closer the information moves together in the volume. The finer the resolution gets the more accurate it will represent its volume data.

The illustration above represents a voxel grid with the data in the center of each cube (point). Storing data in a regular grid offers many benefits in accessing this data at a later time. Traversing such a structure is very simple and fast each neighbor is known and it is very simple to skip across huge volumes as well.
However, some important rules and guidelines of storing and gathering the data need to be laid out because we are talking here volumes and not discrete points. When particles need to gather values form voxels or when particles need to store values in voxels it needs to be clear what happens when multiple values are present in the same region of the volume.
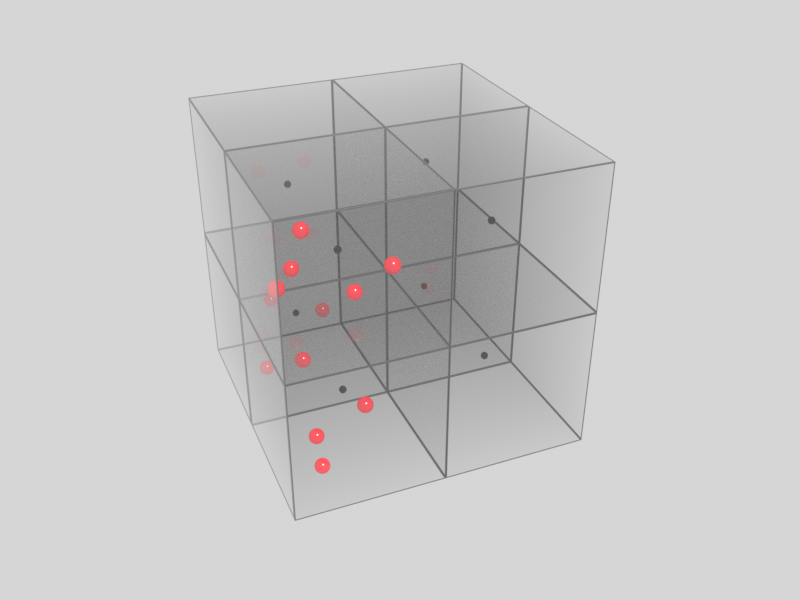
As shown in the illustration above, many particles (red) can exist in one voxel, particles can travel from one voxel to another and so on. Also keep in mind voxel size also plays an important role, the smaller the voxels the less likely you might have multiple particles in one voxel. Usually such situations are solved in either a simple summation of values or just replacing an existing value with another one.
Retrieving information from the volume Grid is usually done by using some sort of interpolation between multiple voxels or just by gathering the value of the closest voxel and using the distance to the center point of the voxel as a weighting factor.
Despite the performance advantages offered by OpenVDB, it was not designed with GPUs in mind.
The NanoVDB library, originally developed at NVIDIA, is a new addition to the ASWF’s OpenVDB project. It provides a simplified representation that is completely compatible with the core data structure of OpenVDB, with functionality to convert back-and-forth between the NanoVDB and the OpenVDB data structures, and create and visualize the data.
NanoVDB employs a compacted, linearized, read-only representation of the VDB tree structure (Figure 1), which makes it suitable for fast transfer and fast, pointer-less traversal of the tree hierarchy. The data stream is aligned for efficiency and can be used on GPUs and CPUs alike.
In short - NanoVDB is a highly optimized subset of OpenVDB, optimized to leverage the power of highly parallel processing which is perfect for the GPU. However, NanoVDB does not necessarily need a GPU to operate, it performs reasonably well on CPU. The main use for NanoVDB is the fast visualization of massive OpenVDB data structures.
GPU accelerated NanoVDB functionality in thinkingParticles is offered through the use of the fastest and most advanced Unbiased Physically Based Spectral renderer available for 3ds Max: finalRender.
But there is more; finalRender is the only renderer offering trueHybrid™ rendering technology. You get the best of both worlds - all of the time - CPU or GPU. By leveraging the rendering power of your CPU and GPU at the same time, finalRender squeezes every available bit of processing power out of your Workstation.